Abstract
Tactile information plays a crucial role in human manipulation tasks and has recently garnered increasing attention in robotic manipulation. However, existing approaches mostly focus on the alignment of visual and tactile features and the integration mechanism tends to be direct concatenation. Consequently, they struggle to effectively cope with occluded scenarios due to neglecting the inherent complementary nature of both modalities and the alignment may not be exploited enough, limiting the potential of their real-world deployment.
In this paper, we present ViTaS, a simple yet effective framework that incorporates both visual and tactile information to guide the behavior of an agent. We introduce Soft Fusion Contrastive Learning, an advanced version of conventional contrastive learning method and a CVAE module to utilize the alignment and complementarity within visuo-tactile representations. We demonstrate the effectiveness of our method in 12 simulated and 3 real-world environments, and our experiments show that ViTaS significantly outperforms existing baselines.
Method
ViTaS takes vision and touch as inputs, which are then processed through separate CNN encoders. Encoded embeddings are utilized by soft fusion contrastive approach, yielding fused feature representation for policy network. A CVAE-based reconstruction framework is also applied for cross-modal integration.
Real-World Experiments
To further assess ViTaS's capability in extracting and integrating multimodal features across diverse scenarios, we adopt Diffusion Policy for real-world evaluations. As illustrated below, we replace DP’s original CNN and transformer encoders with those from ViTaS, while retaining the same training procedure for soft fusion contrastive and CVAE modules as in simulation.
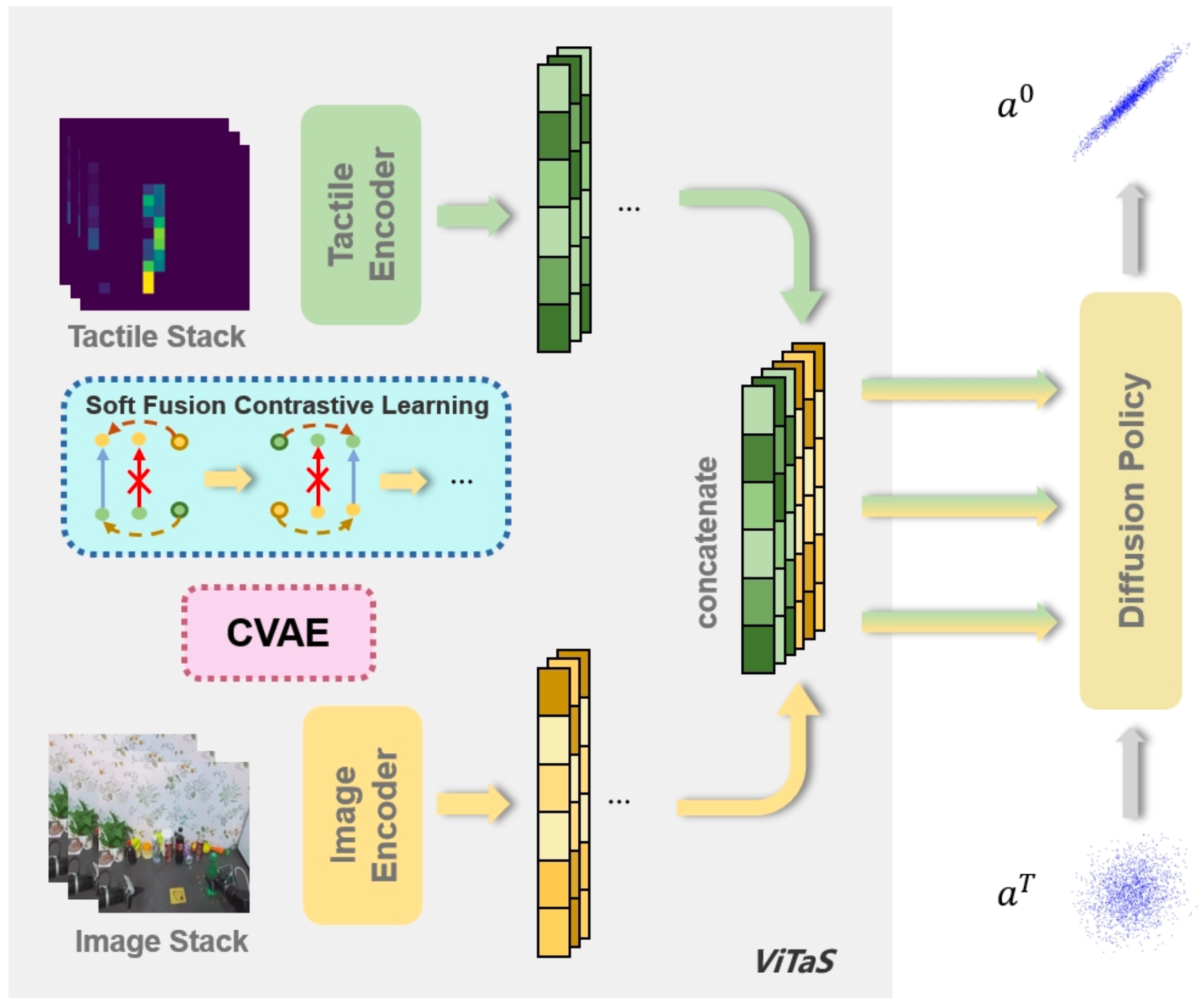
ViTaS in imitation learning based on diffusion policy
We use Galaxea-R1 Humanoid Robot for manipulation, with 3D-ViTaC tactile sensors attached to the end effector.

Real-world setup for ViTaS.
Simulation Experiments
We evaluate on 12 simulated tasks from various benchmarks, including: dexterous hand rotation (Gymnasium), contact-rich manipulation (Robosuite), Insertion, Mobile Catching, and Block Spinning. Beyond these foundational experiments, we introduce a series of auxiliary tasks involving altering object shapes in Lift or modifying physical parameters in Pen Rotation.
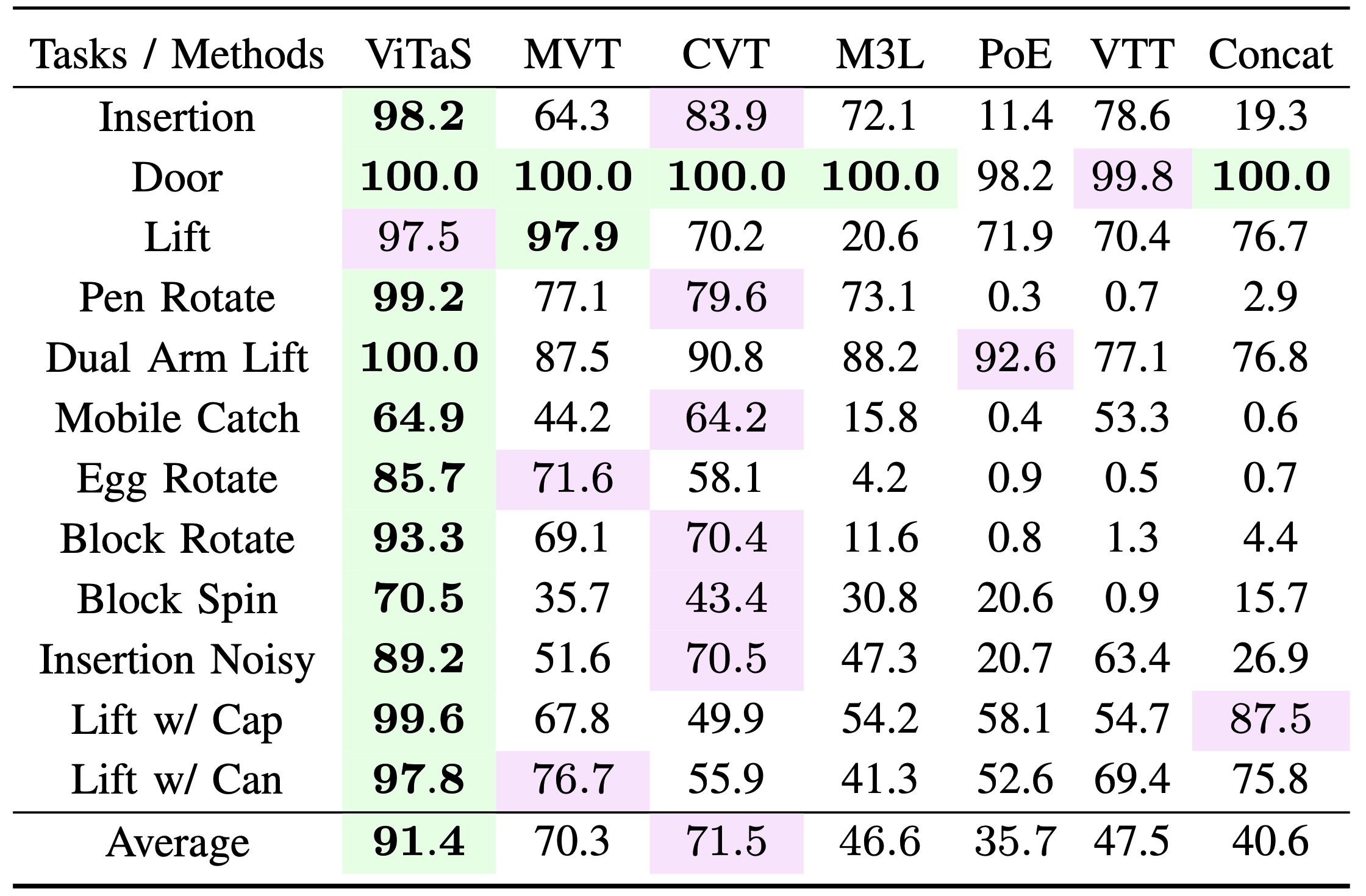
Success rates (%) across 12 simulated tasks
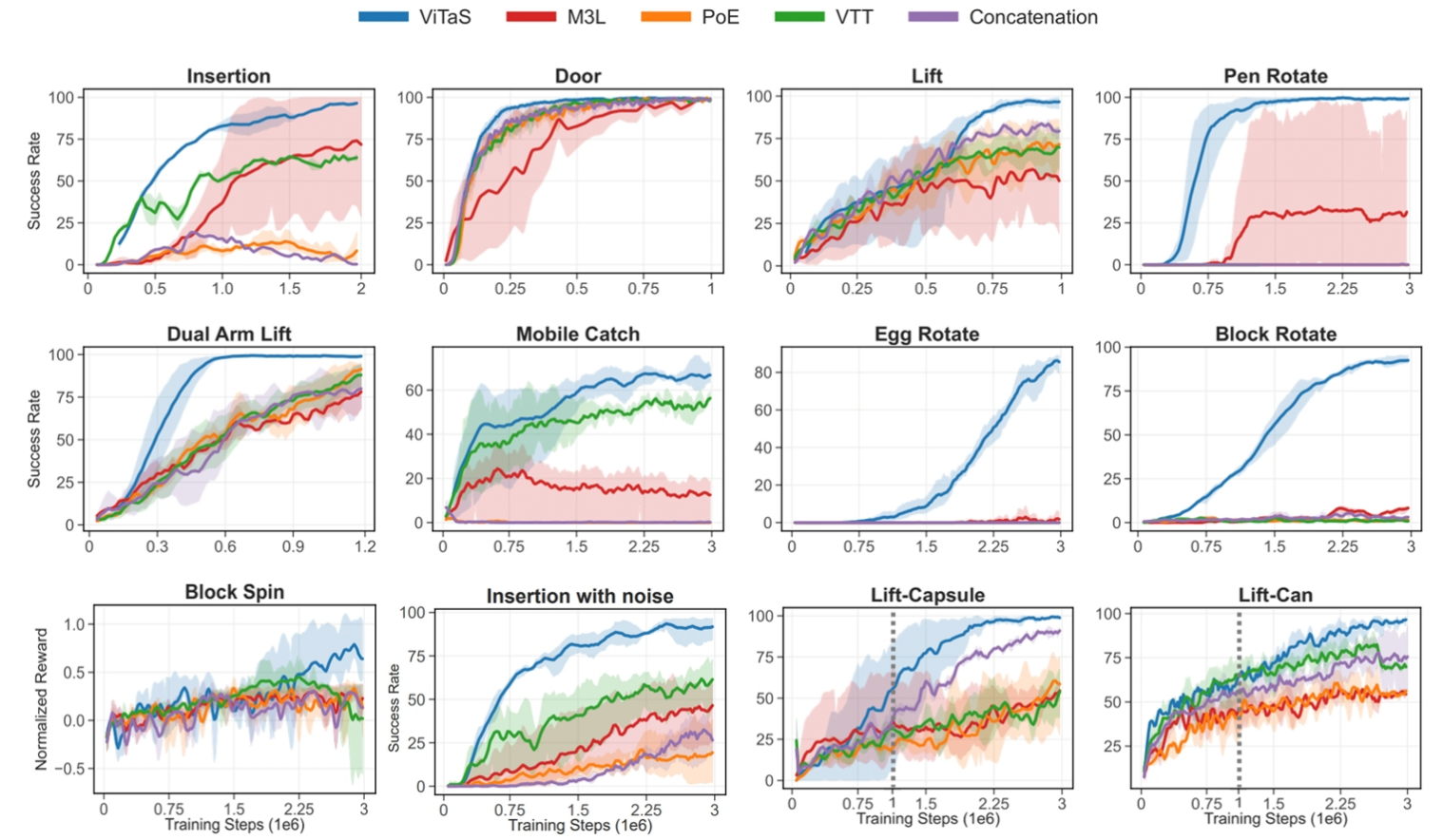
Learning curves